深度学习和神经网络
深度学习是一种实现机器学习的技术,而神经网络是实现深度学习的基本结构。
具体来说:
神经网络:
- 神经网络是一种模仿人脑处理信息方式的计算系统。它由大量的节点(神经元)组成,这些节点通过层次结构相互连接。
- 神经网络可以是浅层的(少数层),也可以是深层的(多层)。浅层神经网络常用于较简单的模式识别和数据分类任务。
深度学习:
- 深度学习是一种机器学习技术,它特别依赖于深层神经网络,即包含多个隐藏层的神经网络。
- 深层神经网络能够学习和模拟数据中的高度复杂的模式和关系,这使得深度学习在图像识别、自然语言处理和许多其他领域非常有效。
关系:
- 所有深度学习模型都是神经网络,但并非所有神经网络都用于深度学习。深度学习特指使用深层神经网络来进行学习和预测的方法。
- 深度学习的“深度”指的是网络的层数。更多的层使得网络能够捕获更复杂、更抽象的数据特征。
神经网络是构成深度学习的基础,而深度学习则是利用这些神经网络来实现复杂任务的学习方法。通过构建和训练深层神经网络,深度学习模型能够学习从简单到复杂的数据模式,解决各种复杂的实际问题。
神经网络和模型
神经网络和模型之间的关系可以这样来阐述:
神经网络:
- 神经网络是一个由多层神经元组成的计算结构,用于模拟复杂的函数映射。每层包含若干神经元,每个神经元通过权重和偏差与其他神经元相连。
- 神经网络的设计(例如,层数、每层的神经元数量、激活函数等)定义了其结构和潜在的计算能力。
模型:
- 当我们谈论“模型”时,通常指的是训练好的神经网络,包括其所有参数(权重和偏差)的特定设置。
- 模型是神经网络训练过程的产物,它捕捉了训练数据中的模式和关系。
训练过程:
- 在训练过程中,神经网络通过调整其权重和偏差来学习数据中的模式。
- 这些调整是通过计算损失函数的梯度并应用优化算法(如梯度下降)来实现的。
- 训练完成后,网络的权重和偏差被“冻结”,形成了最终的模型。
关系和理解:
- 可以将神经网络视为模型的“蓝图”,而训练后的网络则是根据这个蓝图构建的具体实例。
- 模型是训练过程的结果,它包含了为了最大化性能而调整和优化的参数集合。
综上,神经网络在训练过程中自动更新其权重和参数,而训练完成后,这些优化过的权重和参数值构成了最终的模型。这个模型可以用来做预测或进一步分析。
神经网络的学习过程
以图片分类问题为例:
初始状态:
- 在训练开始时,神经网络的权重和偏差通常是随机初始化的。这意味着网络对于分类任务“一无所知”,其初始预测是基于这些随机参数。
喂入数据:
- 然后,我们向网络喂入带有标签的训练数据。在分类问题中,这通常是一组标记了正确类别的图片。
进行预测:
- 对于每张图片,网络根据当前的权重和偏差进行预测,尝试判断图片所属的类别。
- 在 PyTorch 中,相当于
forward()或者model()所做的事情。
计算损失:
- 网络的预测结果会与实际的标签进行比较,使用损失函数来计算预测值和真实值之间的差异。例如,如果使用交叉熵损失函数,在分类问题中,这个函数会衡量网络预测的概率分布与实际标签的概率分布之间的差异。
调整权重和偏差:
- 根据损失函数的结果,网络通过梯度下降(或其他优化算法)来调整其权重和偏差。这个调整是为了减少损失,即减少预测值和真实值之间的差异。
- 这个过程涉及到计算损失函数相对于每个权重和偏差的梯度,然后按这些梯度的反方向来更新参数。
- 在 PyTorch 中,相当于执行
optimizer.step()。
迭代和学习:
- 这个过程在整个训练集上反复进行,网络逐渐学习并提升其预测的准确性。
- 随着训练的进行,网络能够更好地理解数据中的模式和特征,从而在面对新的、未见过的数据时也能做出更准确的预测。
综上,这是一个迭代的学习过程,神经网络通过不断调整自身的参数,以最小化损失函数,进而提高对数据的理解和分类的准确性。
批量学习(Batch Learning)
神经网络在计算损失时通常采用的是分组(批处理)的方式。这种方法被称为批量学习(Batch Learning)。在这种方法中,网络不是对每张图片单独进行预测和计算损失,而是对一组图片(即一个批次)进行预测,然后计算这个批次的总损失。以下是这个过程的关键点:
批处理(Batching):
- 在训练神经网络时,数据通常被分成小批次(batches)。一个批次包含多张图片,批次的大小(即批大小,Batch Size)可以根据需要和硬件资源进行设置。
- 批大小是一个重要的超参数,它影响着模型的内存占用、训练速度和收敛性。
预测和损失计算:
- 网络对整个批次的所有图片同时进行预测。
- 然后,损失函数计算每张图片的预测结果与其实际标签之间的差异,并将这些差异合成整个批次的总损失。在分类问题中,如果使用交叉熵损失函数,这意味着对批次中每张图片的预测概率分布与实际标签的概率分布之间的差异进行计算和求和。
梯度计算和参数更新:
- 根据这个批次的总损失,计算损失相对于网络参数的梯度。
- 这些梯度用于更新网络的权重和偏差,以减少未来预测的总损失。
优势:
- 批处理可以提高数据处理的效率,特别是在使用 GPU 等硬件加速时。
- 它还有助于稳定学习过程,因为每次更新是基于多个样本的平均损失,而不是单个样本的损失。
通过批量处理方法,神经网络在每次更新参数之前,都会考虑一组数据的总体表现,而不是单个数据点。这种方法有助于提高训练的效率和稳定性。
训练数据的顺序
在训练分类模型时,输入数据的随机化(即将不同类别的样本混合)通常是推荐的做法。以下是这种做法的原因:
避免偏见:
- 如果神经网络先训练所有的猫的图片,然后再训练所有的狗的图片,它可能会在训练初期过度适应(即过拟合)猫的特征,从而忽略了狗的特征。这可能导致模型在初始阶段形成偏见,使得后期难以正确学习和识别狗的特征。
提高泛化能力:
- 通过随机混合不同类别的图片,模型能够更平衡地学习各个类别的特征。这有助于提高模型的泛化能力,即在未见过的新数据上的表现。
避免过早收敛:
- 如果数据是有序的,模型可能会在训练的早期阶段过早地收敛到对当前顺序敏感的解决方案。通过随机化数据,可以促使模型探索更多的可能性,从而找到更具泛化性的解决方案。
实践中的操作:
- 在实际操作中,通常会在每个训练周期(epoch)开始前随机打乱数据。这意味着每个批次(batch)中的图片都是随机选择的,包含不同类别的混合。
- 这种方法有助于确保每个类别在整个训练过程中都被公平地表示。
因此,为了获得最佳的训练效果,推荐将不同标签的图片混合在一起,然后进行随机化处理后输入训练。这有助于确保模型能够更有效地学习区分这两个类别的特征。
对神经元的理解
神经元在神经网络中可以看作是一个数学函数。以下是神经元的本质以及权重和偏差在其中的作用:
神经元的本质:
- 神经元(或称为节点)基本上是一个接收输入、产生输出的数学函数。
- 它接收来自前一层神经元的多个输入,这些输入通常是加权和的形式,其中每个输入都被相应的权重所乘。
激活函数:
- 神经元的输出不仅仅是其输入的线性组合。输入的加权和通常会通过一个非线性函数,即激活函数,如 Sigmoid、ReLU 或 tanh 等。
- 这个激活函数使得神经网络能够捕捉和学习复杂的非线性关系。
权重和偏差:
- 权重(Weights)决定了输入信号在影响输出时的强度和重要性。每个输入都有一个相应的权重。
- 偏差(Bias)是加到加权和上的一个常数,它提供了额外的自由度,使得神经元即使在所有输入都是零时也能有非零的输出。
数学表示:
- 从数学的角度来看,一个神经元的操作可以表示为 \(f(w_1x_1+w_2x_2+…+w_nx_n+b)\) ,其中 \(w_1,w_2,…,w_n\) 是权重, \(x_1,x_2,…,x_n\) 是输入, \(b\) 是偏差, \(f\) 是激活函数。
函数的角色:
- 在这个框架下,权重和偏差类似于函数方程的系数和常量,它们调节输入如何影响输出。
- 神经网络通过学习这些权重和偏差的最佳值来拟合和预测数据。
因此,可以将神经元视为一个通过权重和偏差调整其输入的函数,通过激活函数引入非线性,使得整个网络能够学习和模拟复杂的数据关系和模式。
损失函数
损失函数在机器学习和深度学习中扮演着至关重要的角色。它是一个用来衡量模型性能的函数,特别是在模型预测和实际数据之间的差异。以下是损失函数的一些关键特点:
定义:
- 损失函数,有时也被称为代价函数,是一个衡量单个样本预测错误的度量。在给定输入和模型的情况下,损失函数输出一个数值,这个数值表示预测值和真实值之间的差距。
目的:
- 损失函数的主要目的是指导模型的学习。模型训练的目标是最小化损失函数,即减少预测值和真实值之间的差异。
常见类型:
- 均方误差(MSE): 在回归问题中常用,计算预测值和实际值之差的平方的平均值。
- 交叉熵损失: 在分类问题中常用,特别是在二分类或多分类问题中。它衡量的是模型预测的概率分布与实际标签的概率分布之间的差异。
在神经网络中的作用:
- 在神经网络训练过程中,通过计算损失函数并使用诸如梯度下降之类的优化算法来调整网络的权重,使得损失函数的值最小化。
选择损失函数:
- 选择哪种损失函数取决于特定的机器学习任务(如回归、分类、聚类等)和数据特性。
损失函数是连接模型预测和真实数据的桥梁,它提供了一种量化模型性能的方式,使得我们可以通过数学方法来优化模型。
梯度
在神经网络中,梯度是一个非常重要的概念。下面是对梯度及其在神经网络中作用的解释:
梯度的含义:
- 在数学和物理学中,梯度通常指的是一个函数在每个点上的斜率或变化率。在多维空间中,它表示该函数在每个方向上的斜率。
- 在神经网络中,梯度通常指代损失函数(或目标函数)关于网络参数(如权重和偏差)的偏导数。它表明了损失函数在参数空间的每个维度上增加或减少的速率。
梯度在神经网络中的作用:
- 梯度用于优化神经网络的参数。通过计算损失函数相对于每个参数的梯度,神经网络可以了解如何调整其参数以减少总损失。
- 这通常通过一个过程称为梯度下降来完成,其中参数沿着梯度的反方向调整,以减少损失函数的值。
导数、偏导数和梯度
导数(Derivative):
- 导数是一个单变量函数在某一点上的瞬时变化率。它告诉我们,当输入变量发生非常小的变化时,函数值将如何变化。
- 在数学上,如果有一个函数 f(x),那么在点 x 的导数 f′(x) 表示当 x 发生微小变化时,f(x) 的变化量。
偏导数(Partial Derivative):
- 偏导数是多变量函数对其中一个变量的导数,同时假设其他变量保持不变。例如,对于函数 f(x,y),对 x 的偏导数 \(\frac{∂f}{∂x}\) 表示当 x 发生微小变化而 y 保持不变时,函数值的变化率。
- 偏导数描述的是在多维空间中,函数沿着某一个坐标轴的变化率。
梯度(Gradient):
- 梯度是导数在多维空间中的推广。它不是针对单一变量,而是针对多变量函数的每个独立变量的偏导数的集合。
- 在数学上,对于多变量函数 f(x,y,z,…),梯度是一个向量,其每个分量都是对应于一个变量的偏导数。梯度指向函数增长最快的方向。
区别:
- 维度: 导数是一维的,而梯度是多维的。
- 方向: 导数只有大小,没有方向(或者可以说是正或负的方向),而梯度是一个向量,具有大小和方向。
- 应用: 在单变量函数的情境中使用导数,而在多变量函数的情境中使用梯度。
在神经网络的背景下,考虑到网络参数通常是多维的(例如权重矩阵),因此更多地使用梯度而不是单一的导数。梯度指明了在参数空间中减少损失函数的最快路径。
梯度下降(Gradient Descent)
梯度下降算法是一种用于优化神经网络参数的方法,其目的是最小化损失函数。我们可以用一个比喻来理解梯度下降:
想象你在一个山的顶部,目标是到达山谷(这里的山谷代表损失函数的最小值)。但是,你的眼睛被蒙住了,看不到周围的环境。你只能通过感觉脚下的坡度(这就像是梯度)来判断哪个方向是下坡。
检查坡度(计算梯度):
- 在神经网络中,你首先计算损失函数在当前位置(即当前参数值)的梯度。梯度告诉你损失函数上升和下降最快的方向。在我们的比喻中,这就像是感觉脚下地面的坡度,了解哪个方向是下坡。
迈出一步(更新参数):
- 接下来,你会朝着梯度下降最快的方向迈出一步。这一步的大小称为学习率。在神经网络中,这意味着你会根据梯度和学习率来调整网络的权重和偏差。
- 学习率很重要:如果太大,你可能会跨过山谷,错过最低点;如果太小,你则需要很长时间才能到达山谷。
重复过程:
- 重复这个过程,每次都根据损失函数的梯度来更新你的位置(即神经网络的参数),直到你感觉到自己已经到达了山谷(即损失函数不再显著下降)。
总体来讲,梯度下降是一个迭代过程,它通过不断地计算梯度并更新参数,来帮助神经网络找到损失函数的最小值。这个过程就像是在盲目中找到一条通往山谷的路径。
成本表面和等值线图(Cost Surface & Contour Plot)
- 高度代表成本
- 其余两个轴分别为权重 weight、偏差 bias
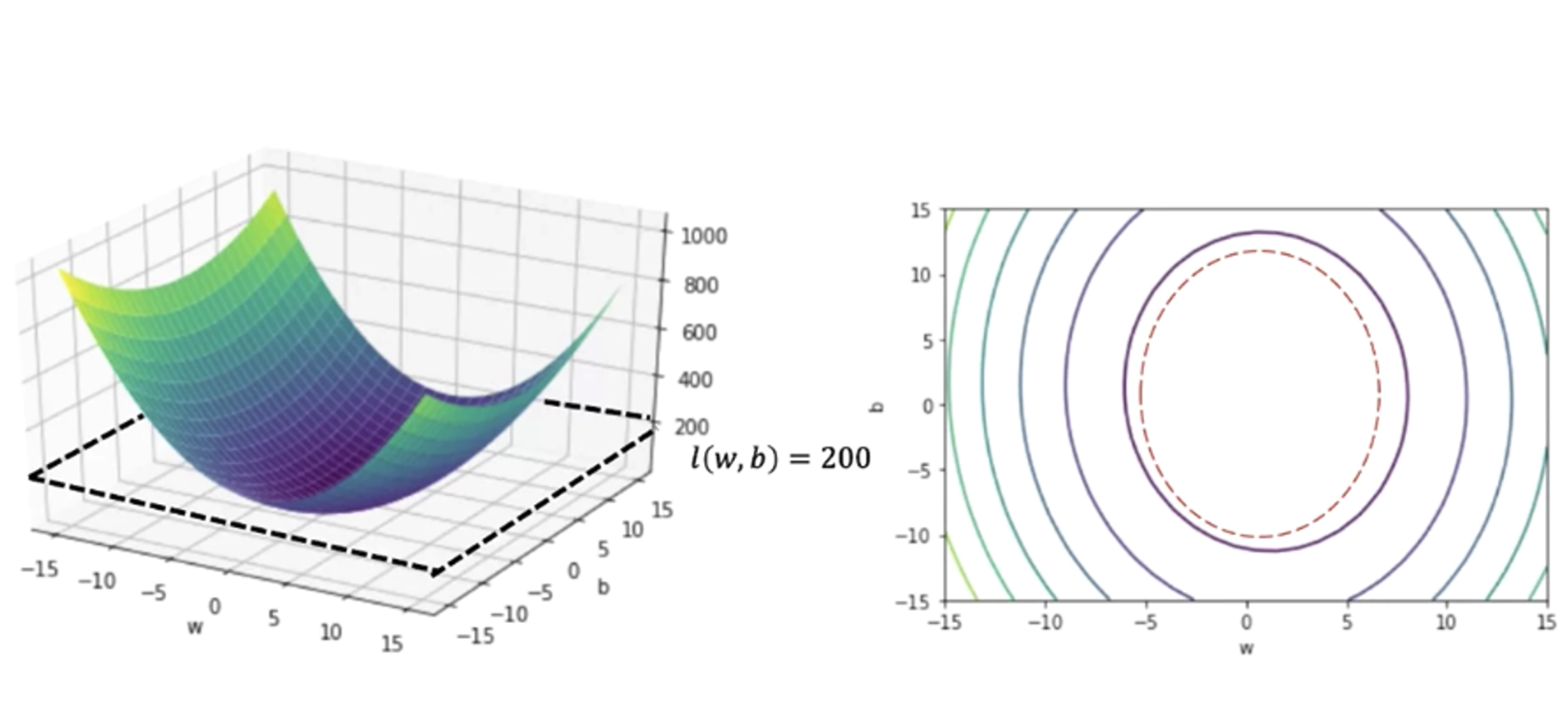
上面两张图有助于理解梯度下降算法(图片参考自 PyTorch Linear Regression Training Slope and Bias )。
上图中的 \(l\)(损失函数)是均方误差(MSE),即:
\[ l(w,b)=\frac{1}{N}\sum_{n=1}^N(y_n-(wx_n+b))^2 \]
学习(训练)的目标,就是找到让这个函数的函数值最小的 w 和 b。
如何根据损失函数的梯度、学习率更新权重
在深度学习中,使用梯度来更新权重是优化模型的关键步骤,这通常在反向传播过程中进行。梯度本质上是损失函数相对于模型权重的偏导数,它指示了损失函数相对于每个权重增加或减少的方向和幅度。通过梯度,我们可以知道如何调整权重以减少损失。
权重更新的基本公式如下:
\[ W_{new}=W_{old}−η⋅∇L(W_{old}) \]
其中:
- \(W_{new}\) 是更新后的权重。
- \(W_{old}\) 是当前的权重。
- η 是学习率。
- \(∇L(W_{old})\) 是损失函数相对于当前权重的梯度。
梯度的作用可以这样理解:
- 方向
- 梯度的方向指向损失函数增长最快的方向。在优化过程中,我们希望减少损失,因此需要向梯度的相反方向更新权重。
- 幅度
- 梯度的幅度(大小)告诉我们在该方向上损失函数变化的速度。如果梯度很大,意味着在那个方向上损失函数变化很快。
学习率的作用:
- 学习率决定了我们在梯度指示的方向上移动的步长。较高的学习率意味着更大的步长,可以加快学习过程,但也可能导致超过最优点,甚至导致模型不稳定。相反,较低的学习率意味着更小的步长,学习过程更稳定,但训练速度会减慢,且可能陷入局部最小值。
因此,选择合适的学习率是非常重要的。太高或太低的学习率都可能导致训练效果不佳。在实践中,通常需要通过实验来确定最佳的学习率。此外,也有一些自适应学习率的优化算法(如 Adam、RMSprop 等),它们可以在训练过程中自动调整学习率,以提高训练的效果和稳定性。
常见的神经网络类型
常见的神经网络类型:
全连接神经网络(Fully Connected Networks):
- 也被称为密集神经网络,是最基本的神经网络形式。在这种网络中,每个神经元与前一层的所有神经元相连。
- 适用于结构化数据,如表格数据或简单的分类任务。
卷积神经网络(Convolutional Neural Networks, CNNs):
- 特别适用于处理图像数据。通过卷积层,CNN 能够捕捉图像中的局部特征。
- 广泛应用于图像分类、物体检测、图像分割等任务。
循环神经网络(Recurrent Neural Networks, RNNs):
- 设计用来处理序列数据,如时间序列数据或自然语言。
- RNN 能够处理输入数据的时间动态特性,适用于语音识别、语言建模等任务。
长短时记忆网络(Long Short-Term Memory, LSTM):
- LSTM 是 RNN 的一种变体,它能够学习长期依赖关系,解决了普通 RNN 难以捕捉长期依赖的问题。
- 常用于复杂的序列任务,如机器翻译、文本生成等。
生成对抗网络(Generative Adversarial Networks, GANs):
- 由两部分组成:生成器和鉴别器。GANs 能够生成新的、与真实数据类似的数据。
- 应用于图像生成、图像风格转换等领域。
变换器网络(Transformer Networks):
- 主要用于处理序列数据,特别是在自然语言处理领域表现出色。
- 依赖于“注意力机制”,能够同时处理整个序列,提高了处理长序列的能力。
这些网络可以根据具体问题和数据类型进行选择和定制。