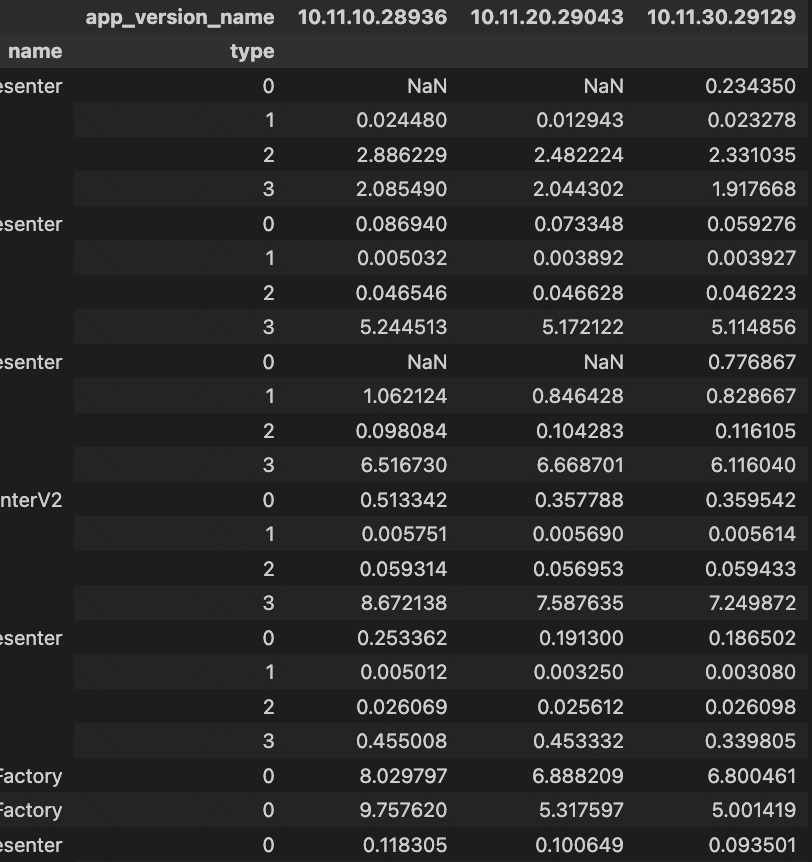
简单任务
数据读取
1 2 3 4 5 6 7 8import pandas as pd df = pd.read_csv('data/android/oom-sessions/oom.csv') # thousands=',' 可以自动将类似 "1,316" 格式的数字转换为整数 df = pd.read_csv('ui-90.csv', thousands=',') df.head()数据过滤
1 2 3 4 5 6 7 8 9 10 11 12 13df = df[df['name']=='ThreadPoolForeg'] # 组合多个条件 df = df[(df.p_date >= 20220830) & (df['count'] >= 200)] # np.isin,保留 name 匹配列表中的名字 df = df[np.isin(df['name'], ['a', 'b', 'c',])] # np.isin, invert,保留 name 不在列表中的 df = df[np.isin(df['name'], ['d', 'e',], invert=True)] # MultiIndex,取第一项做过滤 df = df[np.isin(df.index.get_level_values(0), ['a', 'b', 'c'])]数据排序
1df = df.sort_values(by='size', ascending=False).reset_index(drop=True)行遍历
1 2for index, row in df.iterrows(): print(row['c1'], row['c2'])判断是否是 NaN
1 2 3# 这里 costs 是一个 Series # Series 支持 filter, min 等操作,也支持 costs['10.11.10'] 这种按 key 取值的操作 filtered_obj = filter(lambda a: not math.isnan(a), costs)表的联合
1df = pd.concat([df1, df2], ignore_index=True, sort=False)表合并(类似 SQL 的 join)
1 2# 在多个列上做合并 df = pd.merge(df1, df2, on=['p_date', 'AB实验分组名称'])仅保留某些列、删除某些列
1 2 3 4 5 6 7 8 9 10 11# 保留指定列 df = df[['p_date', 'AB实验分组名称', '点击到用户可见首屏(90分位)', '点击到业务UI可见首屏(90分位)', '点击到用户可见首屏(均值)']] # 删除某些列 df = df.drop('column_name', axis=1) # drop by condition df = df.drop(df[(df.score < 50) & (df.score > 20)].index) # drop by lambda df[df.apply(lambda x: True if (x['cost']) > 6 else False, axis=1)]指定某列的取值,仅保留这些取值的行
1 2 3 4 5# 所有 base 分组 df_base = df.loc[df['AB实验分组名称'].isin(['base1', 'base2'])] # 所有实验分组 df_exp = df.loc[df['AB实验分组名称'].isin(['exp1', 'exp2'])]分别计算某些列的均值
1 2# 分别计算这两列的均值 df1[['duration1', 'duration2']].mean()groupby, agg
1 2 3 4 5 6 7# 按 type 分组,并计算不同 type 的 counts 总和 df = df.groupby(['type'], as_index=False)['counts'].agg( {'sum': 'sum'} ) # 按 name 分组,并按分组分别计算 cost/上报数量 这两列的合 df_names = df.groupby(['name'], as_index=False).agg({'cost': 'sum', '上报数量': 'sum'})rename column name
1df.rename(columns={'oldName1': 'newName1', 'oldName2': 'newName2'}, inplace=True)apply,变换
1 2 3 4 5 6 7 8 9 10 11# 对列 a 应用一个 lambda 表达式 df['a'] = df['a'].apply(lambda x: x + 1) # 删除 name 中 "."及"."前面的字符串 def strip(x): name = x idx = name.rfind('.') if idx >= 0: return name[idx+1:] return name df['name'] = df['name'].apply(strip)replace:列取值的替换
1 2 3 4 5 6 7 8 9 10 11 12>>> df = pd.DataFrame({'col2': {0: 'a', 1: 2, 2: np.nan}, 'col1': {0: 'w', 1: 1, 2: 2}}) >>> di = {1: "A", 2: "B"} >>> df col1 col2 0 w a 1 1 2 2 2 NaN >>> df.replace({"col1": di}) col1 col2 0 w a 1 A 2 2 B NaN
Series
| |
Pivot 透视(旋转)
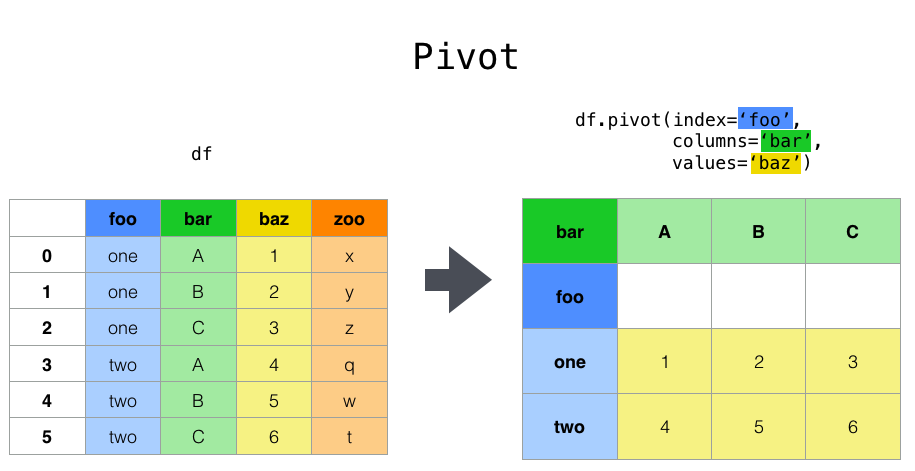
https://pandas.pydata.org/docs/user_guide/reshaping.html
案例:将 app_version_name 的每项取值,转置为列名
| |
变换前:
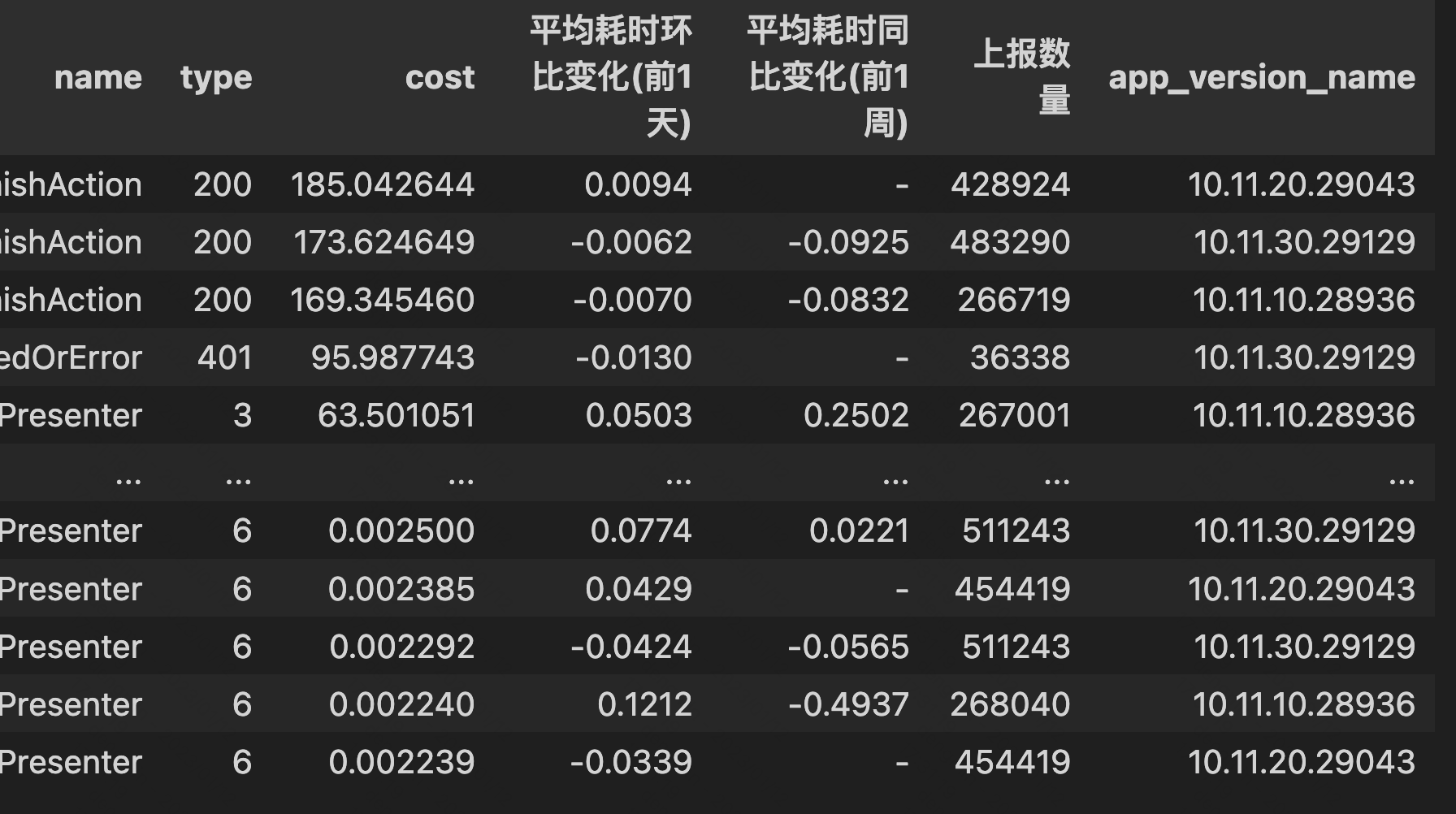
变换后: